Equalizando arquivos do TEMPDB
Olá pessoal,
Depois de um ano de hiato no blog, voltei no sapatinho e agendei alguns posts de assuntos que achei interessante documentar, e o primeiro deles é para trazer algumas informações pertinentes sobre o banco favorito da galera, o TEMPDB, aquele banco de sistema que é utilizado para diversas operações temporárias por toda a instância. Como ele é um recurso global, toda otimização é bem vinda não é mesmo? O assunto do post é o de equalizar o tamanho dos arquivos do TEMPDB, trocando uma ideia sobre alguns pontos que acho interessante compartilhar.
Cenário
No ambiente XYZ que possui um MSSQL 2014, a equipe de banco de dados identificou um ponto de melhoria no (banheiro público) consagrado TEMPDB, que possui quatro (4) arquivos de dados e (1) arquivo de log. Algumas boas práticas já foram aplicadas, como a quantidade de arquivos de dados, a habilitação de trace flags 1117 e 1118, etc pão de queijo e café e muito bom etc.
Um dos pontos que ficou pendente quando a instância nasceu foi a equalização dos arquivos de dados, para que fiquem do mesmo tamanho e daí facilitem a vida do SQL Server, que através do componente interno chamado Storage Engine, faz uso de algoritmos para alocação de páginas que trabalham de mãos dadas, o Round Robin e o Proportional Fill.

Não é objetivo explicar os algoritmos neste post mas de forma resumida, eles garantem que internamente, os dados sejam distribuídos de uma forma mais "equilibrada" entre os arquivos (Round Robin) se utilizando do espaço livre dos arquivos dentro de um mesmo filegroup e preenchendo de forma proporcional e distribuída (Proportional Fill), em outras palavras, evita e/ou mitiga problemas de contenção/performance.
Hands-on
Bem, pra facilitar toda a explicação, nada melhor que imagens, certo? Vamos de ambiente de teste para simular a equalização.
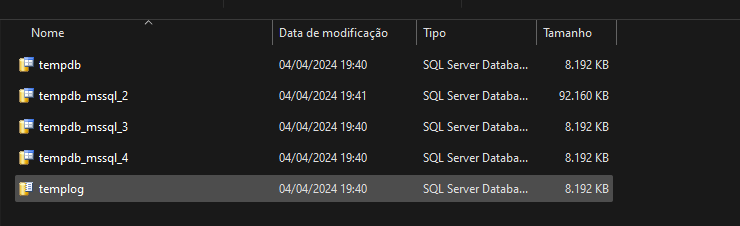
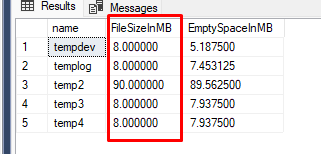
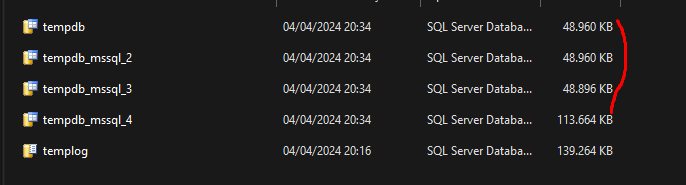
Essa é a visão do Windows. Vamos a visão dentro do SQL pra ver o tamanho atual dos arquivos na sys.database_files :
SELECT name, size/128.0 FileSizeInMB,
size/128.0 - CAST(FILEPROPERTY(name, 'SpaceUsed') AS int)/128.0
AS EmptySpaceInMB
FROM sys.database_files;
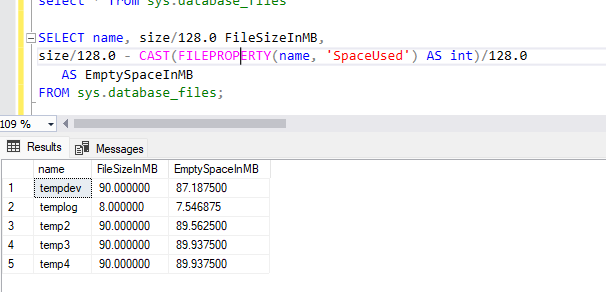
Bem, com o serviço do SQL Server em execução e sem reiniciar o serviço, a forma mais simples de equalizar os arquivos é equalizar se baseando pelo maior arquivo:
- Identificar o maior arquivo (no caso é o tempdb_mssql_2 com 90 MB)
- Crescer os outros arquivos de dados (ignore que o log existe ali) para o mesmo tamanho através do seguinte comando:
ALTER DATABASE TEMPDB MODIFY FILE (NAME='tempdev', SIZE = 90 MB)
ALTER DATABASE TEMPDB MODIFY FILE (NAME='temp3', SIZE = 90 MB)
ALTER DATABASE TEMPDB MODIFY FILE (NAME='temp4', SIZE = 90 MB)
E o resultado disso que você confere com menos de nove meses:
Até aí sem problemas, aumentar o tamanho dos arquivos em um ambiente "busy" é tranquilo. Mas e se eu quisesse diminuir o tamanho dos arquivos? Bem, trago aqui duas alternativas pra discutirmos e aqui vai ser papo reto:
Alternativa #1: SHRINK
Na minha opinião, qualquer operação de shrink de arquivo de dados que seja antecedida por um expurgo de dados significativo é potencialmente criminoso. Executar SHRINK em arquivos de dados deve ser uma exceção, não regra. Reforço também que quando o assunto é SHRINK no TEMPDB o buraco é mais embaixo, pois além de você dificilmente conseguir o tamanho desejado na operação, ainda pode causar diversos bloqueios na instância (dependendo do workload) durante a tentativa de encolher o arquivo.
Imagine para fins de exemplo que eu me arrependi de crescer todos os arquivos para 90 MB e quero deixá-los com 40 MB. Então vou executar um SHRINK nos arquivos de dados em um horário onde existe uso moderado do TEMPDB em minha instância, o que pode dar errado não é mesmo?
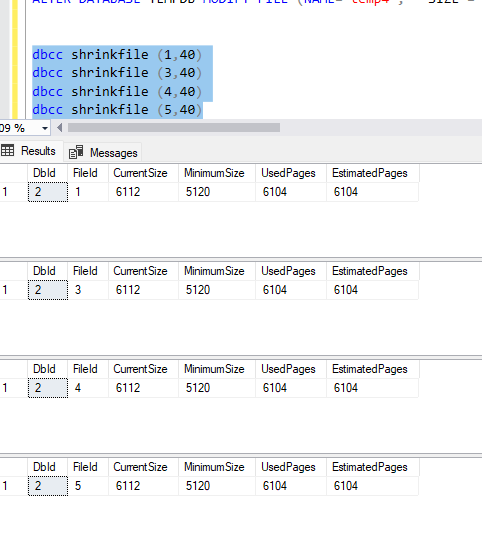
O shrink falhou! E isso costuma acontecer com frequência ao executar em ambientes produtivos.
E aqui vai a primeira pegadinha do malandro que vai fazer mais sentido no cenário #2...Olha o tamanho dos arquivos através de duas views diferentes:
select name, size/128. as SizeMB, 'sys.master_files' as [View]
from sys.master_files where database_id = 2 and type_desc ='rows'
select name, size/128. as SizeMB, 'sys.database_files' as [View]
from sys.database_files where type_desc ='rows'
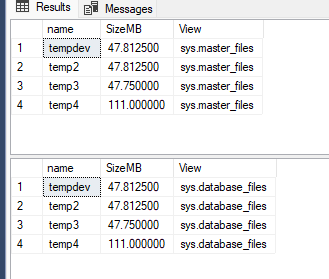
Além de observamos a extremamente mal-sucedida tentativa de encolher os arquivos (algo bem comum em shrink de arquivo de dados) vou jogar no ar uma informação importante sobre as duas views quando o assunto é TEMPDB:
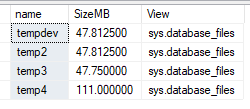
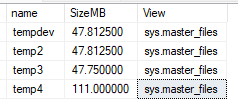
Ambas dizem "Current size" e tudo bem até aí, o problema é que existe uma situação onde o resultado das duas visões apresenta diferença: database_files parece ter mais relação com tamanho atual, e o master_files parece ter mais relação com tamanho "configurado" no fim das contas. Neste caso os tamanhos são iguais então ficou elas por elas, mas prometo que isso vai fazer sentido ao mostrar a alternativa #2, então por enquanto guarde essa lógica...
Enfim, quando temos algum grau de atividade na instância e queremos diminuir o tamanho do arquivo, precisamos de uma janela com menor atividade para tentar reduzir o arquivo via SHRINK. Obviamente, se você pensar "ok posso reiniciar a instância em janela programada e assim que a instância voltar posso fazer um shrink rapidão antes que a porteira das transações volte com força"e é um pensamento válido, mas tem opções melhores se você tem a opção de reiniciar o serviço, o que nos leva a outra alternativa, muito menos pagã!
Alternativa #2 - MODIFY FILE
Aqui é um excelente exemplo de que o TEMPDB é um banco diferenciado, e de vez em quando ele "caga" pra certas regras que o MSSQL usa pra praticamente tudo.
Pois bem, vamos retornar o ambiente ao problema original, que são arquivos de tamanhos diferentes e quero deixá-los do mesmo tamanho, porém quero fazer isso com um tamanho menor que o atual. Bem, para todos os casos eu precisaria de um SHRINK, mas o TEMPDB dá uma "carteirada" nas regras do SQL Server, e permite que façamos a diminuição dele via MODIFY FILE seguindo de um RESTART.
Como diria Datena, bota imagem na tela...
- Aqui temos o ambiente inicial, com arquivos em tamanhos diferentes:
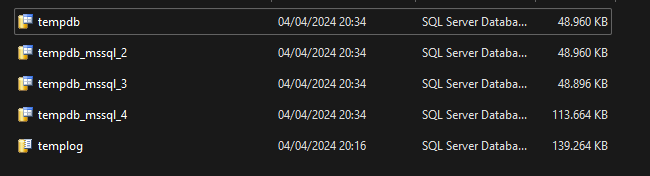
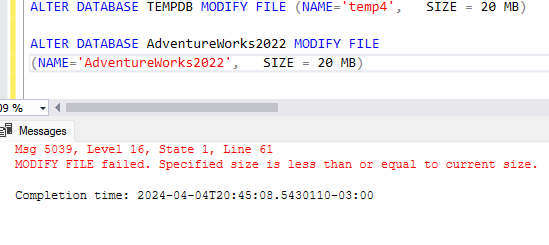
2. Quero padronizar todos os arquivos de dados para 20 MB, e pra isso vou utilizar o MODIFY FILE. Bem, para qualquer outro banco de dados de usuário, se você tentar MODIFICAR o tamanho do arquivo para um tamanho MENOR, vai pipocar sem dó o seguinte erro na sua tela:
ALTER DATABASE AdventureWorks2022 MODIFY FILE
(NAME='AdventureWorks2022', SIZE = 20 MB)
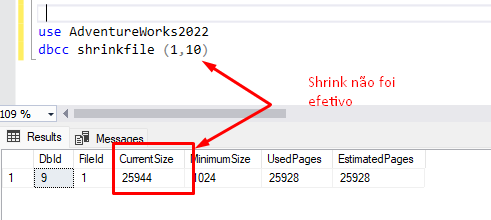
Shrink também não é efetivo, já que não é possível reduzir o arquivo para um valor menor do que o que está sendo utilizado:
E faz sentido certo? Esse comportamento inclusive está bem documentado no comando ALTER DATABASE, e também em documentação ensinando como diminui o tamanho do TEMPDB (https://learn.microsoft.com/pt-br/sql/relational-databases/databases/shrink-tempdb-database?view=sql-server-ver16).
Então, Será que o MODIFY FILE para um tamanho menor funciona no TEMPDB?
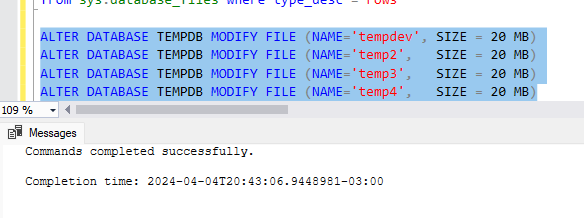
O comando é executado com sucesso, mas note que o tamanho atual dos arquivos permanece o mesmo. E sim, você pode dar um MODIFY pra "um tamanho menor que o atual" independente se tiver muita ou pouca atividade no seu servidor se você estiver se perguntando sobre workload (rolou essa pergunta numa call e achei legal colocar aqui).
Nada acontece feijoada? O SQL Server "configurou" os novos tamanhos e a alteração vai surtir efeito quando o TEMPDB for recriado, e sabemos que ele sempre é recriado durante um restart da instância. Vamos agora à pegadinha do malandro do dia:
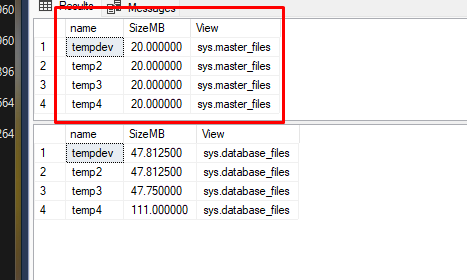
Note que o tamanho atual dos arquivos ainda estão diferentes na database_files que reflete corretamente o tamanho atual. Já na master_files está diferente, pois ela mostra os tamanhos configurados (nem sempre bate com o tamanho atual). Imagino que essa informação não tenha feito muito sentido no exemplo da alternativa #1 Shrink, mas espero que aqui tenha feito total sentido pra você, leitor.
Vamos então reiniciar a instância e conferir se os arquivos de fato são reduzidos, e como o MSSQL e o Windows enxergam o tamanho:
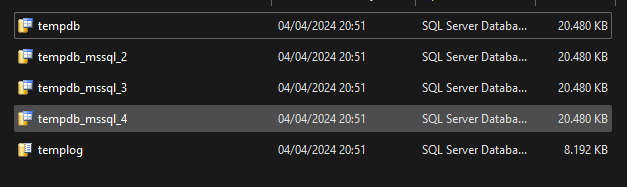
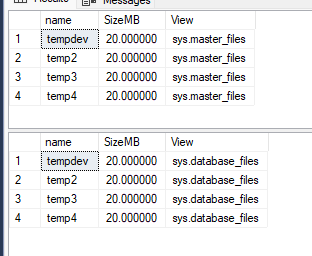
Missão cumprida! O tamanho configurado foi, no final das contas, o tamanho reconfigurado no TEMPDB. Essa solução de fato foi utilizada em um ambiente transacional e de produção, com workload considerável mesmo durante a madrugada, onde um restart é negociável. Muito melhor, mais prático e menos dor de cabeça em comparação com a solução de SHRINK, que acaba sendo a solução do dia a dia de muitos DBA's.
Conclusão
Gostou do post, quer comentar que falei besteira, quer acrescentar algo ou compartilhar alguma experiência sobre o assunto? Fique a vontade e use a caixa de comentário. Agradeço demais pela leitura se você chegou até aqui e peço perdão pelo tamanho do post. Juro que tentei fazer um post menor, escrever (e falar) menos tem sido um objetivo, mas falhei que nem o SHRINK no meio do dia.
[]'s