
Olá,
Continuando a série de posts sobre errorlog (você pode ler a parte 1 clicando aqui), vamos revisitar conceitos mais importantes explicados no post anterior e comentar sobre dicas/boas práticas. Caso hajam testes, indico que devem ser feitos em ambiente de teste (pelo amor de tudo o que você mais ama, rs).
Os tópicos são:
1) Conceito de (Re)Cycle;
2) Aumentar quantidade de ERRORLOGS;
3) Necessidade do ERRORLOG
4) ERRORLOG + DBCC’s
1) Conceito de (Re)Cycle
Conforme post anterior, foi explicado que a geração de arquivos de ERRORLOG possuem uma natureza circular, cujo versionamento obedece uma lógica usando decremento e o processo que realiza a criação dos arquivos se chama Cycle. Creio que reforçar o entendimento sobre o cycle é essencial para entender plenamente como funciona a lógica de geração.
Os eventos de Cycle ocorrem quando:
(1) – O servidor é reiniciado;
(2) – Se estiver em cluster e ocorrer movegroup (mesma coisa do evento 1);
(3) – Forem executados os seguintes comandos: DBCC ERRORLOG e sp_cycle_errorlog
(4) – A partir do SQL Server 2012: Alteração de thresold do tamanho do arquivo. A alteração ocorre via registro. Para maiores informações, veja aqui: http://www.sqlskills.com/blogs/paul/limiting-error-log-file-size-in-sql-server-2012/
Cenário de exemplo
Acabei de instalar uma instância do SQL Server e inicialmente tenho apenas um arquivo de ERRORLOG (apaguei propositalmente os numerados). Reiniciei o serviço e outro arquivo de ERRORLOG é criado, ilustrando perfeitamente o que realmente acontece no processo de cycle: O arquivo atual (ERRORLOG) é versionado para ERRORLOG.1 e um novo ERRORLOG é gerado.
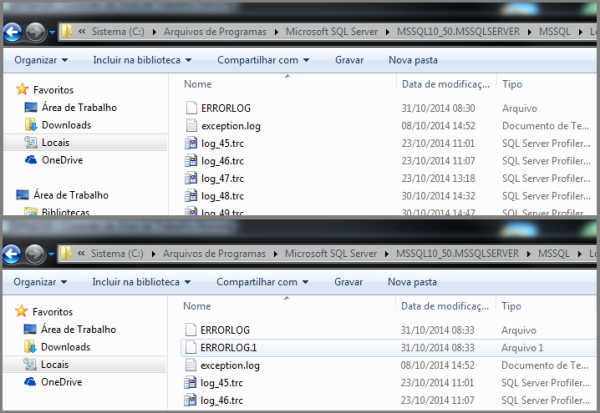
O nome do termo é Cycle embora Recycle também pode ser usado alternadamente (já que ocorre reuso de arquivos além dos nomes lógicos durante o processo).
2) Como aumentar o número de ERRORLOGS gerados
Existem várias formas de aumentar o limite padrão de geração de arquivos de ERRORLOG (6 arquivos numerados + 1 default). O primeiro método é via interface gráfica utilizando o Management Studio:


A interface gráfica é bem intuitiva: Limite o número de arquivos de errorlog antes deles serem reciclados. O valor deve ser entre 6 (totalizando 7 arquivos ao total contando com o arquivo corrente) e 99.
Também é possível realizar essa configuração diretamente pelo registro:
- HKEY_LOCAL_MACHINE\SOFTWARE\Microsoft\Microsoft SQLServer\MSSQL10_50.MSSQLSERVER\MSSQLServer\ onde “MSSQL10_50.MSSQLSERVER” é o nome da instância em questão.

Reforçando que o número de arquivos do ERRORLOG neste caso não considera o arquivo default. Ou seja, doze arquivos totalizam 12 ao todo: 12 numerados e 1 default. O padrão por exemplo é de
6, e isto significa que o limite é de 7 arquivos (6 numerados e 1 default). Você também pode alterar essa configuração de outras formas, utilizando powershell ou T-SQL manipulando o registro por exemplo…
3) Necessidade do ERRORLOG
O errorlog é um arquivo obrigatório para inicialização padrão do SQL Server. Uma das formas de configurar o caminho para o diretório dos errorlogs é realizado pelo SQL Server Configuration Manager:

Caso você altere o caminho utilizado pelo parâmetro -e (de errorlog, obviamente), no próximo startup o SQL Server irá criar, no mínimo, novos arquivos de ERRORLOG, o padrão e o arquivo de No.1 (isso se novo caminho não tenha nenhum arquivo) e seguir com seu funcionamento normal.
Uma dúvida incomum mas já vi perguntarem:
– Eu não uso o ERRORLOG. Posso desabilitar, pois eu não uso e está ocupando espaço, tem problema?
Antes de responder a pergunta, vamos ao primeiro relato:
Caso I – O problema estava no ERRORLOG
Este caso é real, Em 2013 onde trabalhei na empresa Y, e tivemos um incidente em produção em plena sexta-feira no horário de almoço. Alguns serviços caíram sem explicação e todos foram rapidamente resolvidos pela equipe de DBA’s, exceto por uma instância que não subia de jeito nenhum. A instância estava em cluster e por mais que tudo parecesse 100% configurado (revisamos praticamente tudo), a DBA Sênior acabou identificando que o apontamento do SQL Server para o ERRORLOG estava desconfigurado (caminho inválido, não lembro se era falta de uma barra ou se o caminho estava sem o nome errorlog).
Dá pra você simular isso em uma máquina local, apenas altere o caminho do errorlog para um caminho inválido, aplique a mudança, pare e inicie o serviço do SQL Server (e lembre-se de corrigir o problema depois do teste, rs).

Conclusão: Até hoje não sabemos como o problema aconteceu e nem como o cluster estava funcionando, e deduzimos que o caminho sofreu alteração enquanto o serviço estava no ar e apenas no restart o SQL Server utilizou o novo caminho. É vital que o ERRORLOG contenha um caminho válido, pois o serviço SQL Server PRECISA do errorlog em seu funcionamento padrão e desejo que ninguém passe por isso. Mas se passar, pode ser interessante olhar esse detalhe que geralmente não é a primeira coisa a se pensar, pois as mensagens de erro neste caso não são tão específicas.
E sobre a quantidade máxima de ERRORLOGS?
Caso II – Limite de arquivos de ERRORLOG

Qual é o valor recomendado para quantidade de arquivos de errorlog? Tempos atrás conversei com um consultor, fiz essa mesma pergunta e ele me informou que prefere deixar o limite (99). Porém, em um ambiente X onde ele estava prestando consultoria, esqueceu de aumentar esse valor. O ambiente X é um SQL Server em cluster que na ocasião estava instável e a instância em questão movia-se várias vezes durante a madrugada entre os hosts…
E o que acontece em eventos de stop-start e em movegroups?
Cycles! Chuta o que acontece com cycles e o valor de quantidade de arquivos está padrão….
No dia seguinte, a primeira coisa que o consultor fez pra investigar o problema foi entrar no ERRORLOG para investigar possíveis evidências do problema mas não encontrou praticamente nada que pudesse ajudá-lo, pois o servidor já tinha reiniciado tantas vezes que o log mais antigo sequer apontava pra eventos da noite passada. De outras formas, começou a observar o problema e identificou que o problema era thread starvation (e isso explicava os moves). Mas a moral da história é: tudo o que aconteceu nos dias anteriores e estava ali no errorlog não existe mais (nesse caso não se fazia backup de errorlog). São evidências perdidas…Depois do ocorrido, o consultor setou a quantidade de arquivos pra 99 (era uma configuração que ele podia fazer neste ambiente em questão).
Conclusão: deixar o número de arquivos padrão prejudicou a análise do consultor, que conseguiu identificar o problema, mas utilizando outros meios…mas não só isso…sumiu com dias de evidências de logging.
Conclusão: Alguns defendem que ter poucos arquivos de errorlog é útil pois não existe necessidade de historicidade dos registros de ERRORLOGS em seus ambientes (mas essa ideia some rapidinho quando algum problema acontece) e outros argumentam que é interessante sim ter muitos arquivos para manter historicidade e ter respostas de eventos antigos se necessário. Há pessoas que inclusive defendem um cycle todos os dias na calada da noite pra separar os eventos por arquivo utilizando a data (e isso faz sentido, mas não acho que seja uma boa prática geral) para diminuir a ocorrência de logs grandes.
Particularmente, concordo que 7 arquivos (6 numerados e 1 padrão) é um limite baixo e que é interessante de ser aumentado, enquanto noventa e nove (99) é relativamente alto e pode assustar. A opinião de muita gente (e compartilho com ela) é que manter 99 arquivos é melhor do que confiar em apenas 6. Em geral, como o hábito de fazer backup do errorlog é algo bastante incomum, vários profissionais (de acordo com o que leio) setam no limite (99) justamente para não correr o risco de se perder evidências. Acho que é uma abordagem válida desde que se fique de olho na quantidade e tamanho dos arquivos, pois desta forma o reuso de arquivos através dos (re)cycles pode demorar para acontecer, mas não sem antes um plano de expurgo ou backup destes arquivos. Tem pessoas que preferem um meio termo e setam algo em torno de 50 arquivos….Essa é uma decisão de cada um e intimamente relacionada com o uso que cada administrador faz do errorlog. Como está em seu ambiente e porquê? Fique à vontade para comentar sobre, tenho interesse em saber.
3- Personalizando o ERRORLOG
Essa dica é muito útil para quem quer aproveitar mais do ERRORLOG. Existe uma procedure interna bastante utilizada no SQL Server 2000, sumiu no 2005 e que foi reintroduzida no SQL Server 2008 chamada sp_alter_message. A ideia é simples e bastante intuitiva de entender…
Lembram que o primeiro post comentamos sobre a sys.messages?
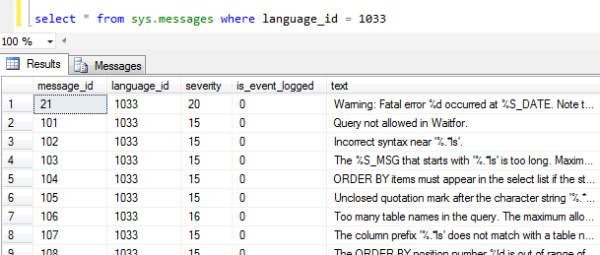
Repare na coluna is_event_logged. É possível, através desta procedure, permitir que certos eventos sejam logados no ERRORLOG conforme necessidade.
Por exemplo, vamos logar as mensagens que indicam comentários que não foram fechados corretamente (/**/). O exemplo não é muito aplicável na vida real, btw, é mais pra facilitar o entendimento:
/* Vamos pesquisar a mensagem "Missing end comment mark"... */ SELECT * FROM sys.messages WHERE 1=1 AND language_id = 1033 AND message_id = 113 /* Flipando o is_event_logged para 1 */ EXEC sp_altermessage @message_id = 113 ,@parameter = 'WITH_LOG' ,@parameter_value = 'true' /* Simulando o erro (execute ignorando o fechamento de comentário) */ /* select 'teste' /* Leia o erro */ SP_READERRORLOG 0,1,'Missing end comment mark'
Agora, algo interessante. O que acontece se tentarmos alterar a configuração das mensagens que são logadas por padrão (ou seja, que possuem o is_event_logged) ?
/* Pesquisando pela mensagem: */ SELECT * FROM sys.messages WHERE 1=1 AND language_id = 1033 and text like '%The error log has been reinitialized%' /* Configurando o SQL Server para NÃO logar as mensagens anteriores */ EXEC sp_altermessage @message_id = 17184 ,@parameter = 'WITH_LOG' ,@parameter_value = 'FALSE' /* Simular um cycle, que é um evento que gera essa mensagem */ SP_CYCLE_ERRORLOG
Então, teoricamente a mensagem não deveria ser logada, certo?
Certeza?
sp_readerrorlog 0,1,’The error log has been reinitialized’
|
LogDate |
ProcessInfo |
Text |
|
2014-11-05 18:13:19.230 |
Spid54 |
The error log has been reinitialized. See the previous log for older entries. |
A mensagem foi logada. A pergunta é, qual motivo?
Vamos simular o mesmo erro através do RAISEERROR:
RAISERROR (17184,10,1)
|
LogDate |
ProcessInfo |
Text |
|
2014-11-05 18:13:19.230 |
Spid54 |
The error log has been reinitialized. See the previous log for older entries. |
Consulte o errorlog novamente, e a mensagem realmente não foi logada (e seria se o is_event_logged tivesse setado como 1). E se, no comando, forçarmos o log desta?
RAISERROR (17184,10,1) WITH LOG
Agora o log foi forçado. Isso indica que eventos que são logados por padrão, mesmo setados para 0, podem logar se o trecho de código de determinado evento explicitar que ele faça isso. Ou seja, mesmo que desabilitemos certas mensagens que não queremos ver no errorlog, mas na chamada de código tiver algum comando que exiga o logging, esta chamada terá prevalência.
Outro exemplo de configurações que possibilitam essa prevalência em relação ao ERRORLOG são os Trace Flags, que também controlam determinados eventos que vão (ou não) para o log. Um dos exemplos mais clássicos é TF 3226, que NÃO loga mensagens de backups realizados com sucesso (backups com falhas continuam sendo logados).
Outra possibilidade são as configurações realizadas via Management Studio, no contexto de servidor:. Um exemplo já velho conhecido de alguns, é o de registrar eventos de login com sucesso, sem sucesso ou ambos:

Dica: Logging on Demand – RAISERROR
Seguindo essa mesma lógica, você pode forçar via RAISERROR que mensagens sejam logadas. Isso significa que as possibilidades de agregar valor ao ERRORLOG são inúmeras, dependendo do ambiente e necessidades de cada um. Imagine por exemplo, que você tenha um job que realiza verificação de páginas em SUSPECT. Vai depender da sua implementação, mas você pode, por exemplo, consultar a saída deste comando direto no errorlog:
Um exemplo de uso:
DECLARE @Contagem AS INT = (SELECT COUNT(1) FROM MSDB.DBO.SUSPECT_PAGES) DECLARE @msgFechamento AS VARCHAR(100) = 'Verificação de ambiente: Suspect Pages: '+CAST(@Contagem as CHAR(3)) RAISERROR (@msgFechamento,10,1) WITH LOG
Tem quem use essa velha e conhecida técnica para fins de debug e tem quem use para logar mensagens de negócio importantes (como por exemplo, resultados de fechamentos financeiros) mas esse último, particularmente, acho uma má ideia no geral, pois o errorlog é essencialmente um log do SQL Server como Infraestrutura e destinado para administradores de banco, ou seja, acho que se perde muito o sentido de misturar informação negocial com informação de infraestrutura (em sinceras palavras, vira bagunça, IMHO) e penso que mensagens relacionadas à infraestrutura (como o exemplo da suspect pages) são mais aplicáveis na vida real. Mas, cada ambiente é um ambiente diferente, com necessidades diferentes, então quem sabe haja aplicação para alguém, então fica aqui a dica.
O próximo post será o último d trilogia e vai apresentar motivos e estratégias relacionadas ao Errorlog na prática: estratégias para aproveitá-lo da melhor forma possível. Quero trazer um algoritmo (beta) que administra os errorlogs de uma forma diferente e que pode ajudar alguém.
Fique à vontade para comentar (dúvidas, críticas, sugestões, etc) enquanto a terceira parte está em produção.
[]’s
Referências:
– Sys.messages: http://msdn.microsoft.com/pt-br/library/ms187382.aspx
– Alterando quantidade de errorlogs: http://support.microsoft.com/kb/196909
– Threshold Errorlog: http://www.sqlskills.com/blogs/paul/limiting-error-log-file-size-in-sql-server-2012/
Pingback: Controlando o crescimento do ERRORLOG | DBCC BLOG('SQL Server')
Pingback: ERRORLOG – Parte 3: Na prática › Renato Siqueira